Understanding Teiid Engine
- Overview
- DQPCore
- Request
- RequestWorkItem
- Process of generate a ProcessorPlan
- 1. Parsing - validate SQL syntax and convert to internal form.
- 2. Resolving - link all identifiers to metadata and functions to the function library
- 3. Validating - validate SQL semantics based on metadata references and type signatures.
- 4. Rewriting - rewrite SQL to simplify expressions and criteria
- 5. Optimizing - the logical plan and processor plan
- Query Processor
- Teiid Query Engine
Overview
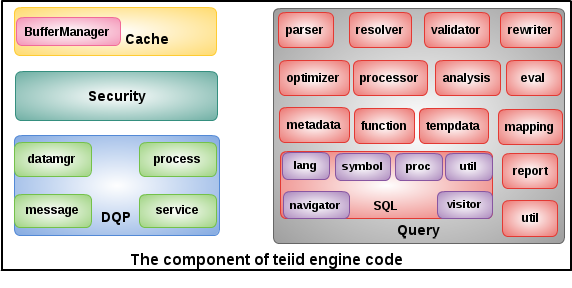
As per figure above, the component of teiid engine code mainly be categorized into 4 parts:
- Cache - the key cache api and implementation
- Security - the key security api
- DQP - the implementation of client DQP, and internal process logic
- Query - the core of teiid engine, it including a series of compnments
This article mainly dive into the underlying of these components.
DQPCore
DQPCore is the entry point of Teiid Engine Procesing, it implement the client interface DQP. A client JDBC query will first go into
ResultsFuture<ResultsMessage> executeRequest(long reqID, RequestMessage message) throws TeiidProcessingException, TeiidComponentException;
If debug the DQPCore, set a breakpoint to this method is smart way.
DQPCore start
The DQPCore start initialize lots of necessary components which used in Teiid Engine, it mainly including BufferManager initialize, TempTableDataManager initialize etc.
TempTableDataManager initialize
TempTableDataManager is used to handle temporary tables, What temporary tables are defined in System Metadata. TempTableDataManager initialize need a DataTierManagerImpl as blow code:
DataTierManagerImpl processorDataManager = new DataTierManagerImpl(this, this.bufferManager, this.config.isDetectingChangeEvents());
processorDataManager.setEventDistributor(eventDistributor);
dataTierMgr = new TempTableDataManager(processorDataManager, this.bufferManager, this.rsCache);
In DataTierManagerImpl’s constructor method, all systemTables and systemAdminTables be load to memory, it including SystemTables:
VIRTUALDATABASES,
SCHEMAS,
TABLES,
DATATYPES,
COLUMNS,
KEYS,
PROCEDURES,
KEYCOLUMNS,
PROCEDUREPARAMS,
REFERENCEKEYCOLUMNS,
PROPERTIES,
FUNCTIONS,
FUNCTIONPARAMS,
and SystemAdminTables:
MATVIEWS,
VDBRESOURCES,
TRIGGERS,
VIEWS,
STOREDPROCEDURES,
USAGE
Each Tables represent by a RecordExtractionTable
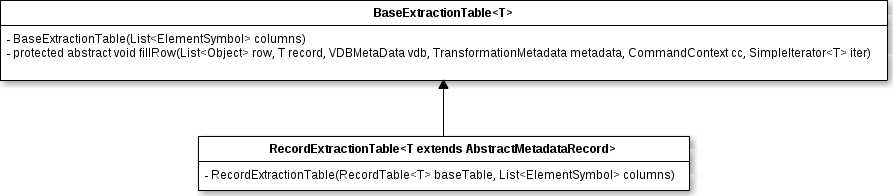
The RecordTable looks

DQPCore’s executeRequest() method
public ResultsFuture<ResultsMessage> executeRequest(long reqID,RequestMessage requestMsg) throws TeiidProcessingException
The executeRequest() is the entrance of any Client SQL Request. A simple message holder org.teiid.net.socket.Message (which wrapped the this method’s name, request ID and the RequestMessage) received by transport layer(netty server), then DQPCore’s executeRequest() be invoked by java reflection.
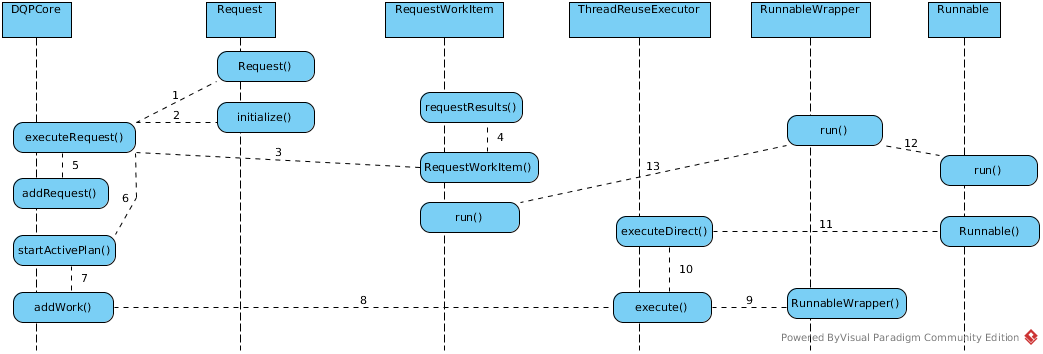
- Reuqest’s initialize() - initialize the RequestMessage, BufferManager, ProcessorDataManager, etc
- RequestWorkItem’s constructor - initialize the DQPCore, RequestMessage, Request, etc, and invoke requestResults(), sent the startRow and endRow base on FetchSize
- addRequest() - put the “requestID -> RequestWorkItem” to it’s ConcurrentHashMap, and put “requestID” to ClientState’s HashSet
- addWork() - invoke ThreadReuseExecutor’s execute, “RequestWorkItem” be passed as parameter.
- execute() - A RunnableWrapper be fistly created, then invoke executeDirect(), RunnableWrapper be passed as parameter.
- executeDirect() - Change the
submittedCount,activeCountandhighestActiveCountof ThreadReuseExecutor, if activeCount equals maximumPoolSize queue theRunnableWrapper, then create a Runnable, summit the Runnable to Process Worker Threads Pool - Process Worker Thread Run - Runnable implementation, RunnableWrapper, RequestWorkItem all has a run() method, Process Worker Thread Run procedure like:
Runnable's run() -> RunnableWrapper's run() -> RequestWorkItem's run()
RequestWorkItem’s run() has more details about query plan running.
DQPCore’s executeQuery() method
DQPCore supply a static public method executeQuery(), which used to execute the given query asynchly.
public static ResultsFuture<?> executeQuery(final String command
, final VDBMetaData vdb
, final String user
, final String app
, final long timeoutInMilli
, final DQPCore engine
, final ResultsListener listener) throws Throwable
DQPWorkContext
DQPWorkContext is ThreadLocal variable, its mainly supply functionalities including:
- keep all Session, connection information related information before Request be transfer to Processing Threads.
- Supply the interface to run
CallableandRunnabletask.
DQPWorkContext run Callable example:

Request
Once the client SQL query be passed to Teiid Engine(DQPCore), it first be formed as a org.teiid.dqp.internal.process.Request Object, which is the Server side representation of the RequestMessage, the UML diagram of Request:
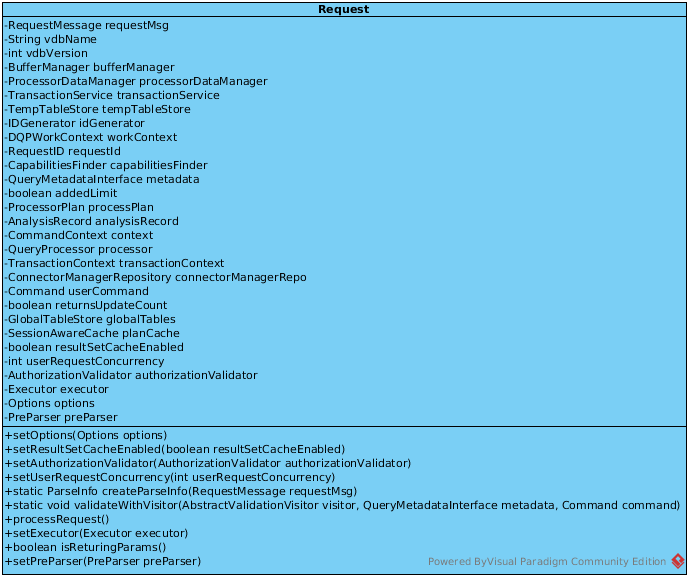
initialize
Request first be created, the initialize() be invoked, passed the following parameters:
RequestMessage- contains client request, sql, etcBufferManager- use to batch/memory control/processingProcessorDataManager- use to interact with connector layer, retrieve data from underlying data sourcesTransactionService- transaction related actionsTempTableStore- act as full resource manager.DQPWorkContext- use to get session/connection information(more details)SessionAwareCache- PreparedPlan cache
Also, the requestId, connectorManagerRepo which contains connection info be initialize.
This method invoked by Netty NIO Work Threads(more details about thread pools in Teiid Engine).
process Request
After Request and RequestWorkItem be initialized correctly, Request’s processRequest() be invoked by Process Worker Threads(more details about thread pools in Teiid Engine).
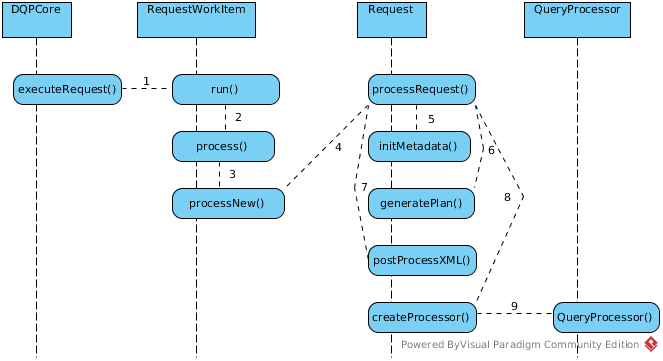
processRequest() is the key operation method. This method will finally create org.teiid.query.processor.QueryProcessor, which wrappered a org.teiid.query.processor.ProcessorPlan(Refer to Process of generate a ProcessorPlan for more details).
processRequest() mainly do 3 aspects task:
initialize Metadata
- initialize a CapabilitiesFinder, used to to find connector capabilities.
- initialize a QueryMetadataInterface, used to get metadata in runtime, refer to Understanding Teiid Metadata for more details.
- initialize a GlobalTableStore, use to get TableStore and metadata.
Process of initializing the capabilities for translator-mysql
The ‘capabilities’ means underlying sources’ capabilities, these capabilities mainly depicted by translator, each translator has defined a series of properties used to depict the capabilities of source.
A interface org.teiid.query.optimizer.capabilities.SourceCapabilities define 5 methods to get sources’ capabilities:
public boolean supportsCapability(Capability capability);
public boolean supportsFunction(String functionName);
public Object getSourceProperty(Capability propertyName);
public boolean supportsConvert(int sourceType, int targetType);
public boolean supportsFormatLiteral(String literal, Format format);
The supportsCapability method used to judge whether a Capability are supported, the capabilities including:
QUERY_SELECT_DISTINCT
QUERY_SELECT_EXPRESSION
TableAlias
MAX_QUERY_FROM_GROUPS
JOIN_CRITERIA_ALLOWED
QUERY_FROM_JOIN_INNER
QUERY_FROM_ANSI_JOIN
SelfJoins
QUERY_FROM_JOIN_OUTER
InlineViews
QUERY_FROM_JOIN_OUTER_FULL
CRITERIA_BETWEEN
CRITERIA_COMPARE_EQ
CRITERIA_COMPARE_ORDERED
LikeCriteria
LikeCriteriaEscapeCharacter
CRITERIA_IN
CRITERIA_IN_SUBQUERY
CRITERIA_ISNULL
CRITERIA_OR
CRITERIA_NOT
CRITERIA_EXISTS
CRITERIA_QUANTIFIED_SOME
CRITERIA_QUANTIFIED_ALL
CRITERIA_ONLY_LITERAL_COMPARE
QUERY_ORDERBY
QUERY_ORDERBY_UNRELATED
QUERY_ORDERBY_NULL_ORDERING
QUERY_ORDERBY_DEFAULT_NULL_ORDER
QUERY_AGGREGATES
QUERY_GROUP_BY
QUERY_HAVING
QUERY_AGGREGATES_SUM
QUERY_AGGREGATES_AVG
QUERY_AGGREGATES_MIN
QUERY_AGGREGATES_MAX
QUERY_AGGREGATES_ENHANCED_NUMERIC
QUERY_AGGREGATES_COUNT
QUERY_AGGREGATES_COUNT_STAR
AggregatesDistinct
QUERY_SUBQUERIES_SCALAR
QUERY_SUBQUERIES_CORRELATED
QUERY_CASE
QUERY_SEARCHED_CASE
QUERY_UNION
QUERY_INTERSECT
QUERY_EXCEPT
QUERY_SET_ORDER_BY
QUERY_FUNCTIONS_IN_GROUP_BY
BATCHED_UPDATES
BULK_UPDATE
ROW_LIMIT
ROW_OFFSET
MAX_IN_CRITERIA_SIZE
CONNECTOR_ID
REQUIRES_CRITERIA
INSERT_WITH_QUERYEXPRESSION
INSERT_WITH_ITERATOR
COMMON_TABLE_EXPRESSIONS
MAX_DEPENDENT_PREDICATES
AdvancedOLAP
QUERY_AGGREGATES_ARRAY
ElementaryOLAP
WindowOrderByAggregates
CRITERIA_SIMILAR
CRITERIA_LIKE_REGEX
DEPENDENT_JOIN
WindowDistinctAggregates
QUERY_ONLY_SINGLE_TABLE_GROUP_BY
ONLY_FORMAT_LITERALS
CRITERIA_ON_SUBQUERY
ARRAY_TYPE
QUERY_SUBQUERIES_ONLY_CORRELATED
QUERY_AGGREGATES_STRING
FULL_DEPENDENT_JOIN
SELECT_WITHOUT_FROM
QUERY_GROUP_BY_ROLLUP
QUERY_ORDERBY_EXTENDED_GROUPING
INVALID_EXCEPTION
COLLATION_LOCALE
RECURSIVE_COMMON_TABLE_EXPRESSIONS
EXCLUDE_COMMON_TABLE_EXPRESSION_NAME
CRITERIA_COMPARE_ORDERED_EXCLUSIVE
PARTIAL_FILTERS
DEPENDENT_JOIN_BINDINGS
SUBQUERY_COMMON_TABLE_EXPRESSIONS
SUBQUERY_CORRELATED_LIMIT
NO_PROJECTION
REQUIRED_LIKE_ESCAPE
QUERY_SUBQUERIES_SCALAR_PROJECTION
TRANSACTION_SUPPORT
QUERY_FROM_JOIN_LATERAL
QUERY_FROM_JOIN_LATERAL_CONDITION
QUERY_FROM_PROCEDURE_TABLE
QUERY_GROUP_BY_MULTIPLE_DISTINCT_AGGREGATES
UPSERT
The CapabilitiesFinder define methods to get SourceCapabilities:
public SourceCapabilities findCapabilities(String modelName) throws TeiidComponentException;
public boolean isValid(String modelName);
The CapabilitiesFinder has implementation org.teiid.dqp.internal.process.CachedFinder and org.teiid.query.metadata.TempCapabilitiesFinder, the process Request initialize Metadata initialize the TempCapabilitiesFinder which contain a delegate CachedFinder.
Assuming mysql 5 are used, below is the process of initializing the capabilities for translator-mysql
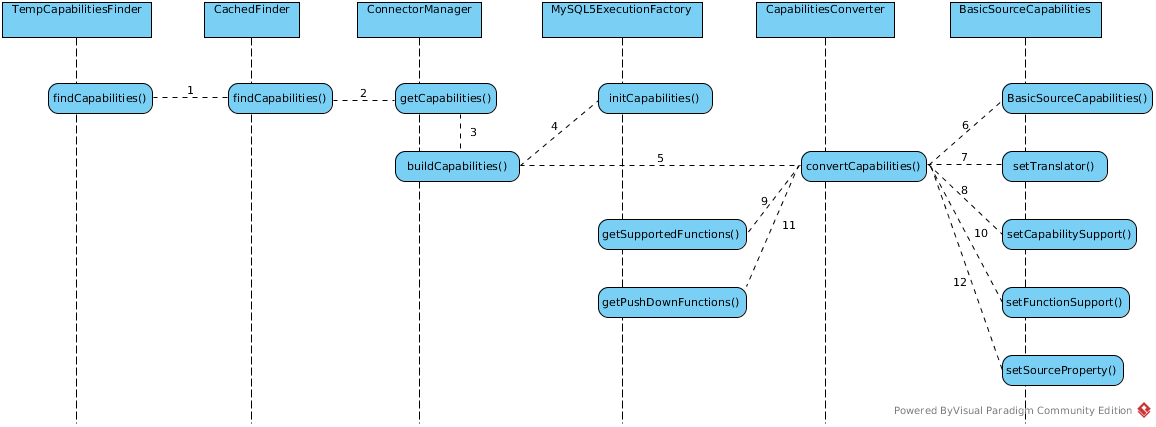
The BasicSourceCapabilities mainly contain 3 maps(capabilityMap, functionMap, propertyMap) to keep source’s capabilities. By default mysql5 translator defined connector capabilities including`:
- capabilities - {QUERY_AGGREGATES_AVG=true, QUERY_UNION=true, CRITERIA_ONLY_LITERAL_COMPARE=false, BULK_UPDATE=true, QUERY_ORDERBY_UNRELATED=true, QUERY_ORDERBY_NULL_ORDERING=false, SelfJoins=true, CRITERIA_QUANTIFIED_SOME=true, QUERY_INTERSECT=false, CRITERIA_SIMILAR=false, QUERY_SEARCHED_CASE=true, INSERT_WITH_ITERATOR=true, TableAlias=true, QUERY_AGGREGATES_MAX=true, QUERY_AGGREGATES_STRING=false, CRITERIA_QUANTIFIED_ALL=true, DEPENDENT_JOIN=false, QUERY_AGGREGATES_ARRAY=false, QUERY_FROM_JOIN_INNER=true, QUERY_SUBQUERIES_CORRELATED=true, QUERY_FROM_JOIN_OUTER=true, RECURSIVE_COMMON_TABLE_EXPRESSIONS=false, QUERY_ORDERBY=true, LikeCriteria=true, QUERY_HAVING=true, CRITERIA_COMPARE_ORDERED=true, COMMON_TABLE_EXPRESSIONS=false, QUERY_FROM_JOIN_OUTER_FULL=false, CRITERIA_ISNULL=true, ROW_OFFSET=true, CRITERIA_IN=true, SELECT_WITHOUT_FROM=true, LikeCriteriaEscapeCharacter=true, QUERY_SUBQUERIES_ONLY_CORRELATED=false, QUERY_FROM_PROCEDURE_TABLE=false, ONLY_FORMAT_LITERALS=false, InlineViews=true, CRITERIA_IN_SUBQUERY=true, CRITERIA_COMPARE_EQ=true, REQUIRES_CRITERIA=false, ElementaryOLAP=false, QUERY_GROUP_BY_MULTIPLE_DISTINCT_AGGREGATES=true, AggregatesDistinct=true, QUERY_GROUP_BY=true, CRITERIA_LIKE_REGEX=true, ARRAY_TYPE=false, BATCHED_UPDATES=true, QUERY_AGGREGATES_MIN=true, CRITERIA_NOT=true, ROW_LIMIT=true, SUBQUERY_COMMON_TABLE_EXPRESSIONS=false, QUERY_AGGREGATES_COUNT=true, QUERY_SELECT_DISTINCT=true, QUERY_AGGREGATES_COUNT_STAR=true, QUERY_AGGREGATES_ENHANCED_NUMERIC=true, FULL_DEPENDENT_JOIN=false, QUERY_AGGREGATES_SUM=true, CRITERIA_COMPARE_ORDERED_EXCLUSIVE=true, UPSERT=false, QUERY_EXCEPT=false, INSERT_WITH_QUERYEXPRESSION=true, CRITERIA_EXISTS=true, QUERY_FROM_JOIN_LATERAL_CONDITION=false, QUERY_GROUP_BY_ROLLUP=true, QUERY_SET_ORDER_BY=true, QUERY_ONLY_SINGLE_TABLE_GROUP_BY=false, CRITERIA_ON_SUBQUERY=true, SUBQUERY_CORRELATED_LIMIT=true, QUERY_SELECT_EXPRESSION=true, QUERY_FROM_JOIN_LATERAL=false, CRITERIA_OR=true, QUERY_FROM_ANSI_JOIN=false, QUERY_SUBQUERIES_SCALAR_PROJECTION=true, QUERY_FUNCTIONS_IN_GROUP_BY=false, QUERY_ORDERBY_EXTENDED_GROUPING=false, QUERY_SUBQUERIES_SCALAR=true}
- functions - {*=true, +=true, -=true, /=true, abs=true, acos=true, ascii=true, asin=true, atan=true, atan2=true, bitand=true, bitnot=true, bitor=true, bitxor=true, ceiling=true, char=true, coalesce=true, concat=true, convert=true, cos=true, cot=true, dayname=true, dayofmonth=true, dayofweek=true, dayofyear=true, degrees=true, exp=true, floor=true, hour=true, ifnull=true, insert=true, lcase=true, left=true, length=true, locate=true, log=true, log10=true, lpad=true, ltrim=true, minute=true, mod=true, month=true, monthname=true, mysql.timestampdiff=true, pi=true, power=true, quarter=true, radians=true, repeat=true, replace=true, right=true, round=true, rpad=true, rtrim=true, second=true, sign=true, sin=true, sqrt=true, st_asbinary=true, st_astext=true, st_geomfromtext=true, st_geomfromwkb=true, st_srid=true, substring=true, tan=true, timestampadd=true, trim=true, ucase=true, week=true, year=true}
- properties - {EXCLUDE_COMMON_TABLE_EXPRESSION_NAME=null, REQUIRED_LIKE_ESCAPE=null, JOIN_CRITERIA_ALLOWED=ANY, CONNECTOR_ID=[translator-mysql, java:/accounts-ds], MAX_DEPENDENT_PREDICATES=50, COLLATION_LOCALE=null, TRANSACTION_SUPPORT=XA, MAX_IN_CRITERIA_SIZE=1000, MAX_QUERY_FROM_GROUPS=-1, QUERY_ORDERBY_DEFAULT_NULL_ORDER=LOW}
generate Plan
GEnerate Plan first create a CommandContext which carry the processing related information, including GlobalTableStore, ProcessorBatchSize, etc.
Refer to Process of generate a ProcessorPlan for details.
Create QueryProcessor
Base on Process of generate a ProcessorPlan steps generated ProcessorPlan, create a org.teiid.query.processor.QueryProcessor:
this.processor = new QueryProcessor(processPlan, context, bufferManager, processorDataManager);
TempTableStore
TempTableStores are transanctional, but do not act as full resource manager. This means we are effectively 1PC and don’t allow any heuristic exceptions on commit. Table state snapshoting and a javax.transaction.Synchronization are used to perform the appropriate commit/rollback actions.
NOTE: refer to link for more about JTA Synchronization.
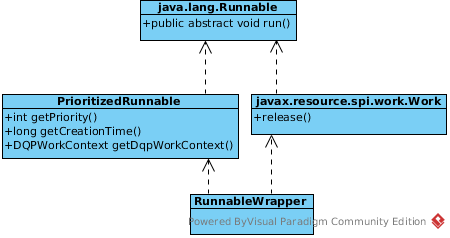
RequestWorkItem
RequestWorkItem implements Runnable interface, it be executed by Processing threads in processWorkerPool(more details about thread pool refer to Threads in Teiid Engine below). The main functionality supplied by RequestWorkItem including:
- Compiles results for the client
- Collects Tuples froming batchs
- Prevents buffer growth
Attributes of RequestWorkItem:

Threads in Teiid Engine
There are 3 kinds of threads:

-
Netty Worker Threads - the work related with Engine Process are execute DQPCore’s executeRequest() method, init the
RequestandRequestWorkItem, then start theRequestWorkItemwhich wrapped a active processor plan. -
Process Worker Threads - RequestWorkItem, run the process request, rule-based optimization, etc. processWorkerPool used maintain these threads, the init of the processWorkerPool like:
ThreadPoolExecutor tpe = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 2, TimeUnit.MINUTES, new SynchronousQueue<Runnable>(), new NamedThreadFactory("Worker"));
- corePoolSize is 0 means the processWorkerPool do not keep any idle threads
- maximumPoolSize is 2147483647 means the maximum number of threads to allow in pool is 2147483647.
- keepAliveTime is 2 and time unit is minutes means the idle threads will be keep 2 minutes then be exit.
- Source Query Worker Threads - Used to retrive tuple’s from DataSources, interacted with Connector layer(translator and resource adapter) via ConnectorWork API. Learn more from sequence diagram. Source Query Worker Threads also maintained by processWorkerPool.
RequestWorkItem’s run()
RquestWorkItem run by Process Worker Thread:
- startProcessing() - sent
isProcessingtotrue; changethreadStatefromMORE_WORKtoWORKING; - process() - if
stateisNEW, change toPROCESSING, invoke processNew(); ifstateisPROCESSING, invoke processMore(); - processNew() - Check the result cache; Process the Request, generate a proessor plan(Refer to Process of generate a ProcessorPlan;
//TODO– finished at processNew(), next time start from BatchCollector create.
send Results If Needed
This should only be called from Process Worker Threads, ResultsReceiver’s receiveResults(T results) method be invoked, set the results to org.teiid.client.util.ResultsFuture’s result if they have been requested.
ThreadState Change Change in Request Processing
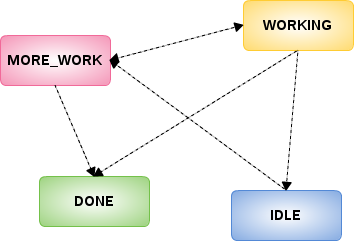
Rules of ThreadState Change
1. Process Threads startProcessing change ThreadState from MORE_WORK to WORKING
Any threads start execute the RequestWorkItem, its ThreadState Must be MORE_WORK, then change to WORKING
2. Process Threads endProcessing change ThreadState to DONE or IDLE
- if RequestWorkItem’s ThreadState is WORKING and Processing is Done, change ThreadState to DONE
- if RequestWorkItem’s ThreadState is WORKING and Processing is NOT Done, change ThreadState to IDLE
- if RequestWorkItem’s ThreadState is MORE_WORK and Processing is Done, change ThreadState to DONE
3. moreWork() method change ThreadState to MORE_WORK
Both Query Thread and Close Request Thread will invoke RequestWorkItem’s moreWork(), change ThreadState to MORE_WORK:
- Query Threads invoke moreWork() - Once Query Thread finished Query(If DataTierTupleSource’s
cancelAsynchis false, or If RequestWorkItem’sisProcessingis true) execute RequestWorkItem’smoreWork(), and if ThreadState is WORKING or IDLE, change to MORE_WORK - Close Request Thread invoke moreWork() - Once RequestWorkItem’s
requestClose()request, it will execute RequestWorkItem’smoreWork(), and if ThreadState is WORKING or IDLE, change to MORE_WORK
Process of generate a ProcessorPlan
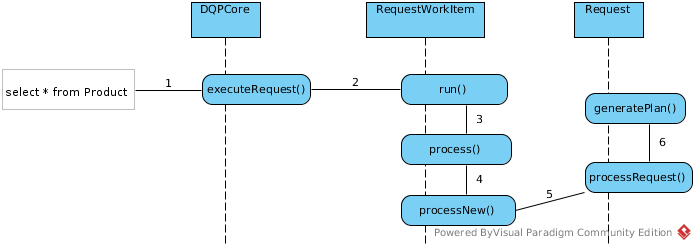
As above figure, assuming a JDBC client execute SQL
SELECT ID, SYMBOL, COMPANY_NAME FROM Product
When the query engine receives an incoming SQL query, it be processed to Request’s generatePlan() method, this method will create a ProcessorPlan(UML diagram), which is a set of instructions created by a query engine for executing a command submitted by a user or application. The purpose of the query plan is to execute the user’s query in as efficient a way as possible.
In this section, we will focus on the process of generate a ProcessorPlan, it performs the following operations:
1. Parsing - validate SQL syntax and convert to internal form.
SQL come from RequestMessage which transited from Client. ThreadLocal QueryParser has a parseCommand() method, which can parse SQL String to internal form, eg, org.teiid.query.sql.lang.Command, refer to link for more forms.
NOTE: QueryParser has a javacc SQLParser.jj based SQLParser, the parse result is a Command Object.
2. Resolving - link all identifiers to metadata and functions to the function library
The QueryResolver is used between Parsing and QueryValidation,
QueryResolver.resolveCommand(command, metadata);
QueryResolver contains a series of CommandResolver(UML) which used to implement Resolver by SQL Types(queries, inserts, updates and deletes).
after resolving, the format of command looks like
SELECT Accounts.PRODUCT.ID, Accounts.PRODUCT.SYMBOL, Accounts.PRODUCT.COMPANY_NAME FROM Accounts.PRODUCT
3. Validating - validate SQL semantics based on metadata references and type signatures.
AbstractValidationVisitor visitor = new ValidationVisitor();
ValidatorReport report = Validator.validate(command, metadata, visitor);
A org.teiid.query.validator.ValidationVisitor is used in Validating, ValidatorReport contain result of Validating.
4. Rewriting - rewrite SQL to simplify expressions and criteria
QueryRewriter is used, which define a series of static methods
public static Command rewrite(Command command, QueryMetadataInterface metadata, CommandContext context, Map<ElementSymbol, Expression> variableValues)
public static Command rewrite(Command command, QueryMetadataInterface metadata, CommandContext context)
public QueryCommand rewriteOrderBy(QueryCommand queryCommand)
public static void rewriteOrderBy(QueryCommand queryCommand, OrderBy orderBy, final List projectedSymbols, CommandContext context, QueryMetadataInterface metadata)
public static Criteria rewriteCriteria(Criteria criteria, CommandContext context, QueryMetadataInterface metadata)
public static Expression rewriteExpression(Expression expression, CommandContext context, QueryMetadataInterface metadata)
public static Expression rewriteExpression(Expression expression, CommandContext context, QueryMetadataInterface metadata, boolean rewriteSubcommands)
public static Command rewriteAsUpsertProcedure(Insert insert, QueryMetadataInterface metadata, CommandContext context)
The aim of Rewriting is rewrite commands and command fragments to a form that is better for planning and execution. For example, language object From’s clauses list not setted by default, Rewriting will do it.
An example of rewriting inner join
The inner join sql looks like SELECT * FROM MariaDB.T1 INNER JOIN MariaDB.T2 ON MariaDB.T1.a = MariaDB.T2.b, the rewrite sequence like

5. Optimizing - the logical plan and processor plan
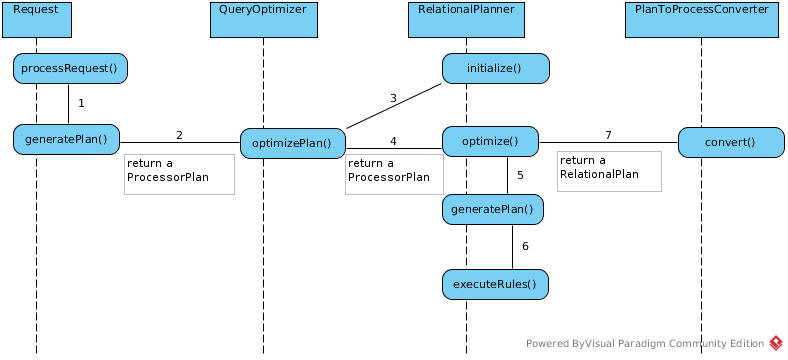
As figure, QueryOptimizer’s optimizePlan() method is the entrence of Optimizing, the main of Optimizing has three primary phases:
- Generate canonical plan
- Optimization
- Plan to process converter - converts plan data structure into a processing form
NOTE: Phase 1 create a logical plan, Phase 2 update logical plan, Phase 3 convert logical plan to processor plan.
Generate canonical plan
This step will convert internal Command to a PlanNode.
With sql SELECT ID, SYMBOL, COMPANY_NAME FROM Product, the relevant Canonical Plan like
Project(groups=[Accounts.PRODUCT], props={PROJECT_COLS=[Accounts.PRODUCT.ID, Accounts.PRODUCT.SYMBOL, Accounts.PRODUCT.COMPANY_NAME]})
Source(groups=[Accounts.PRODUCT])
Refer to Direct Query Source Model Accounts for more details.
If Show Plan and Debug level logging be enabled, Generate canonical plan log can be found like

PlanNode
A PlanNode mainly consist of 3 parts: type, parent PlanNode and children PlanNode list.
There are 12 exist types for each PlanNode:
- NO_TYPE
- ACCESS
- DUP_REMOVE
- JOIN
- PROJECT
- SELECT
- SORT
- SOURCE
- GROUP
- SET_OP
- NULL
- TUPLE_LIMIT
A factory class NodeFactory can create a new PlanNode, the following is a example:
PlanNode node = NodeFactory.getNewNode(NodeConstants.Types.SOURCE);
node.addGroup(new GroupSymbol("Accounts.PRODUCT"));
the output of PlanNode looks
Source(groups=[Accounts.PRODUCT])
A Editor class NodeEditor can find Child Node from a root Node. eg:
List<PlanNode> nodes = NodeEditor.findAllNodes(plan, NodeConstants.Types.PROJECT | NodeConstants.Types.SOURCE)
NOTE: The
PlanNodein this section is underorg.teiid.query.optimizer.relational.plantree, which different withorg.teiid.client.plan.PlanNode.
Optimization
The further Optimizing, all changes are add on PlanNode, two steps involved: build a LIFO Rules stack and execute Rules.
Each rules in stack implement org.teiid.query.optimizer.relational.OptimizerRule,
UML of Rules, all rules are implemented a org.teiid.query.optimizer.relational.OptimizerRule interface which define a execute method
PlanNode execute(PlanNode plan, QueryMetadataInterface metadata, CapabilitiesFinder capabilitiesFinder, RuleStack rules, AnalysisRecord analysisRecord, CommandContext context)
- The execute method return a PlanNode
metadatakeep all metedatacapabilitiesFinderis the entrance of get connector capabilities
The minimal rule stack
Start from Teiid 8.13, there are 28 rules existed, the complexity of rule stack depend on the complexity of sql query, the more complex of sql query(contain join, complexed sub-query, complexted criteria), the more complex of rule stack.
However, as below figure, CollapseSource, PlanSorts, CalculateCost, AssignOutputElements, RaiseAccess, PlaceAccess are the minimal rule stack pattern.

NOTE: The sql query
SELECT ID, SYMBOL, COMPANY_NAME FROM Productwill execute only these 6 rules.
The execution of optimization rules
Note that he rules in Stack executed in a LIFO order, this section will use the rule stack as a example.
PlaceAccess
The PlaceAccess rule places access nodes under source nodes. An access node represents the point at which everything below the access node gets pushed to the source or is a plan invocation. Later rules focus on either pushing under the access or pulling the access node up the tree to move more work down to the sources. This rule is also responsible for placing Access Patterns
Implementation class: org.teiid.query.optimizer.relational.rules.RulePlaceAccess.
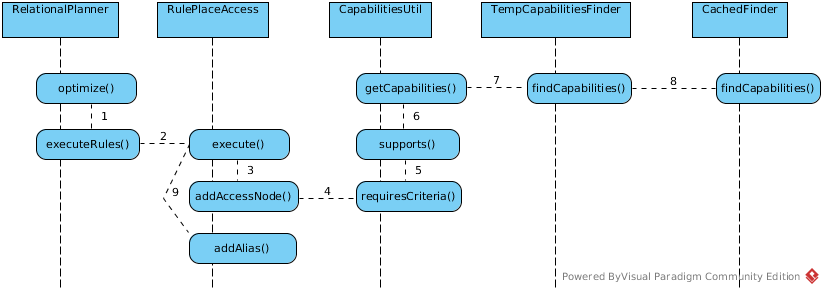
As below sequence figure step 7 - 8, PlaceAccess rule first find the source capabilities, initializing the capabilities for specific source, and cached in a map, more details refer to Process of initializing the capabilities for translator-mysql
Execution log:

RaiseAccess
This rule attempts to raise the Access nodes as far up the plan as possible. This is mostly done by looking at the source’s capabilities and determining whether the operations can be achieved in the source or not.
Implementation class: org.teiid.query.optimizer.relational.rules.RuleRaiseAccess.
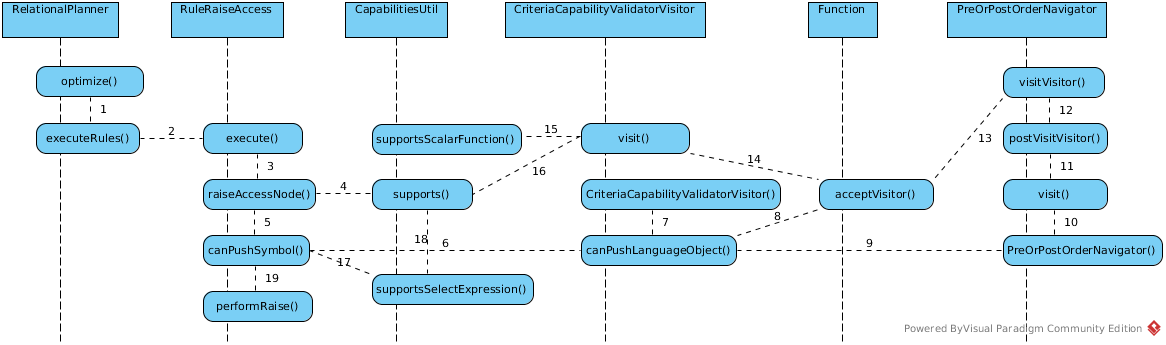
Execution log:

AssignOutputElements
This rule walks top down through every node and calculates the output columns for each node. Columns that are not needed are dropped at every node, which is known as projection minimization. This is done by keeping track of both the columns needed to feed the parent node and also keeping track of columns that are “created” at a certain node.
Implementation class: org.teiid.query.optimizer.relational.rules.RuleAssignOutputElements.
Execution log:

CalculateCost
This rule adds costing information to the plan.
Implementation class: org.teiid.query.optimizer.relational.rules.RuleCalculateCost.
Execution log:

PlanSorts
This rule optimizations around sorting, such as combining sort operations or moving projection.
Implementation class: org.teiid.query.optimizer.relational.rules.RulePlanSorts.
Execution log:
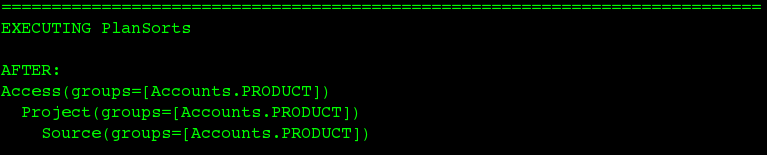
CollapseSource
This rule takes all of the nodes below an access node and creates a SQL query representation.
Implementation class: org.teiid.query.optimizer.relational.rules.RuleCollapseSource.
Execution log:

NOTE: so far, the PlanNode be updated completely, rule-based optimization finished. Run PortfolioQueryPlanner as java Application will simulate these steps.
Plan to process converter
As above Generate canonical plan genrated a canonical plan firstly, which represent by a PlanNode, then as optimization, canonical plan be optimized by optimization rule stack, after these 2 steps finished, plan to process converter will start.
The results of this step will produce a ProcessorPlan(UML diagram).
The UML of Java Class used in this section:
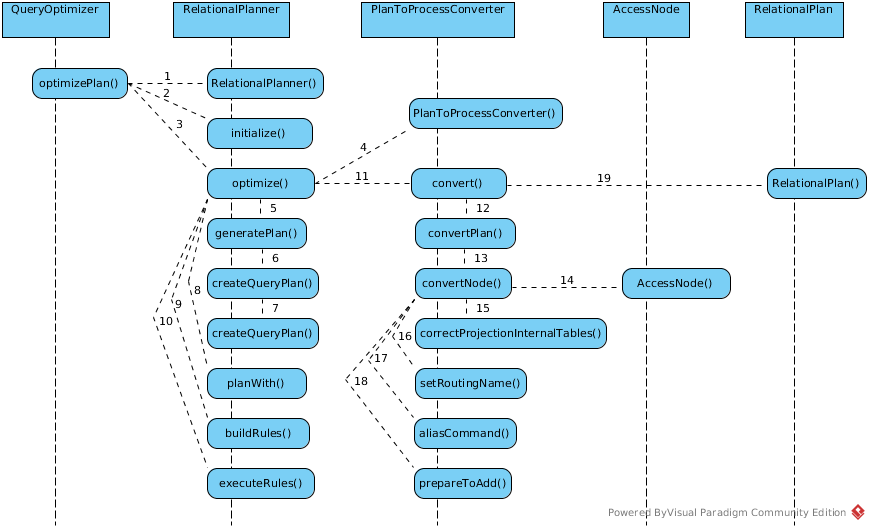
PlanNode be firstly convert to Process Tree, a AccessNode(UML), debug logs like
============================================================================
CONVERTING PLAN TREE TO PROCESS TREE
PROCESS PLAN =
AccessNode(0) output=[Accounts.PRODUCT.ID, Accounts.PRODUCT.SYMBOL, Accounts.PRODUCT.COMPANY_NAME] SELECT g_0.ID, g_0.SYMBOL, g_0.COMPANY_NAME FROM Accounts.PRODUCT AS g_0
============================================================================
The AccessNote be used as root for a Processor Plan, the final Processor Plan looks
----------------------------------------------------------------------------
OPTIMIZATION COMPLETE:
PROCESSOR PLAN:
AccessNode(0) output=[Accounts.PRODUCT.ID, Accounts.PRODUCT.SYMBOL, Accounts.PRODUCT.COMPANY_NAME] SELECT g_0.ID, g_0.SYMBOL, g_0.COMPANY_NAME FROM Accounts.PRODUCT AS g_0
============================================================================
Query Processor
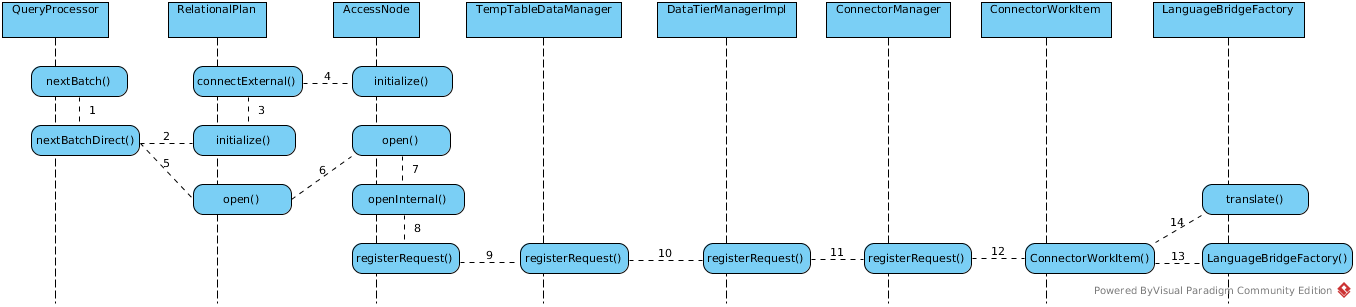
QueryProcessor init
Before QueryProcessor invoke processor plan to get next batch, the QueryProcessor first need be initialized. The main work of QueryProcessor init including:
- initialize processor plan
- initialize language bridge factory, translate sql language to language
BatchCollector collect batchs
BatchCollector used to extract TupleBatchs from DataSources and manipulate to a TupleBuffer, as below sequence diagram, BatchCollector mainly contains 3 aspects function:
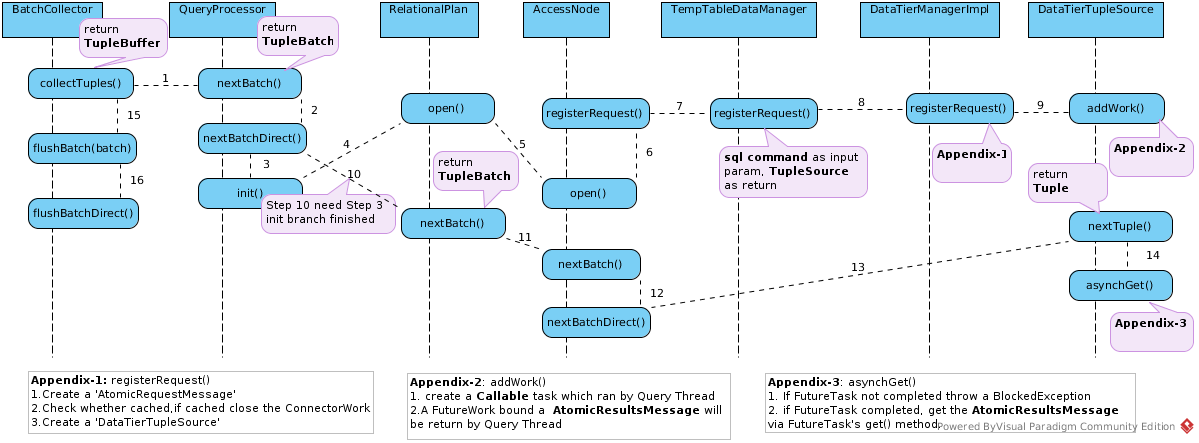
- Start Source Query Threads to return a FutureTask which bound a
AtomicResultsMessage(1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8 ->9). - Check the FutureTask, get the Tuples from
AtomicResultsMessage, assemble all Tuples to a TupleBatch(10 -> 11 -> 12 -> 13 -> 14). - Manipulate TupleBatchs to a TupleBuffer(15 -> 16).
Process System Query
As Appendix-1, the usual processing procedures are like: create a AtomicRequestMessage, check the Cache, create a DataTierTupleSource, but if modelName parameter is SYS or SYSADMIN, the processing directly goes into processSystemQuery.
BlockedException
BlockedException is Teiid’s way to release the current thread instead of waiting for a processing resource to complete, like waiting for data from a data source. As above sequence diagram Appendix-3 in DataTierTupleSource’s asynchGet() method, check the futureResult
- If futureResult not done throw
BlockedException, release current thread - If futureResult done, get
AtomicResultsMessageas result return
The reference source code looks:
if (!futureResult.isDone()) {
throw BlockedException.block(aqr.getAtomicRequestID(), "Blocking on source query", aqr.getAtomicRequestID()); //$NON-NLS-1$
}
FutureWork<AtomicResultsMessage> currentResults = futureResult;
futureResult = null;
AtomicResultsMessage results = null;
try {
results = currentResults.get();
The above code copy from DataTierTupleSource’s asynchGet() method.
NOTE:
DataTierTupleSourceare the interactive layer used to interact with Connect layer, which connects, loads the data source.
NOTE: Asynch Query related with a FutureResult.
Teiid Query Engine
Query Sql API
Refer to link