HBase Quick Start
This article contains how to quick start with Standalone HBase.
HBase Quick Start Doc
HBase Installation
Install HBase 1.1.1
Install via
$ tar xzvf hbase-1.1.1-bin.tar.gz
$ cd hbase-1.1.1
Edit ‘conf/hbase-env.sh’ add JAVA_HOME
conf/hbase-env.sh
Edit ‘conf/hbase-site.xml’, add the following for Standalone HBase:
<property>
<name>hbase.rootdir</name>
<value>file:///home/kylin/server/hbase-1.1.1/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/kylin/server/hbase-1.1.1/zookeeper</value>
</property>
Start HBase via
$ ./bin/start-hbase.sh
Install Phoenix to HBase(Optional)
$ tar xzvf phoenix-4.5.0-HBase-1.1-bin.tar.gz
$ cd phoenix-4.5.0-HBase-1.1-bin
$ cp phoenix-4.5.0-HBase-1.1-server.jar ../hbase-1.1.1/lib
NOTE: Restart HBase is necessary, More detailed document refer to Phoenix Installation
Stop HBase via
$ ./bin/stop-hbase.sh
HBase Shell
Use HBase For the First Time Scripts:
$ ./bin/hbase shell
help
create 'test', 'cf'
list 'test'
put 'test', 'row1', 'cf:a', 'value1'
put 'test', 'row2', 'cf:b', 'value2'
put 'test', 'row3', 'cf:c', 'value3'
scan 'test'
get 'test', 'row1'
disable 'test'
drop 'test'
quit
Add Blog Table
Execute the commands in link
https://github.com/jbosschina/basic-hbase-examples/blob/master/etc/blog_sample_data.txt
will cerate blog table, add data to the table.
Use Java operate HBase
Run HbaseQuickStart will execute the following logic as a order:
- create table
- add some data to table
- add some more data
- get row
- delete table
Run BlogClient will query all blog post, which we create in above section.
Apache ZooKeeper
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. More details
Overview
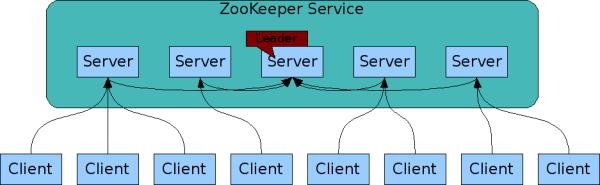
- The servers that make up the ZooKeeper service must all know about each other. They maintain an in-memory image of state, along with a transaction logs and snapshots in a persistent store. As long as a majority of the servers are available, the ZooKeeper service will be available.
- Clients connect to a single ZooKeeper server. The client maintains a TCP connection through which it sends requests, gets responses, gets watch events, and sends heart beats. If the TCP connection to the server breaks, the client will connect to a different server.
Apache Hadoop
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures. More details
Apache Phoenix
Phoenix is an open source SQL skin for HBase. We can use JDBC Acess HBase data, here we demonstrate how to access blog table via JDBC and Phoenix Client Driver. Two Steps can do this:
- Phoenix table to an existing HBase table ‘blog’
create table "blog"(pk VARCHAR PRIMARY KEY, "content" VARCHAR, "info"."author" VARCHAR, "info"."category" VARCHAR);
- JDBC Client execute SQL Query
select * from "blog";